Você sabe o que é Bioinformática?


Olá! Neste artigo vamos falar sobre uma ciência que vem se expandindo bastante nos últimos anos: a Bioinformática.
A Bioinformática é uma ciência inter e multidisciplinar que faz a fusão não só da biologia e da informática, mas também da estatística, matemática, física, química, engenharias, medicina, agricultura entre outras áreas da ciência e tecnologia para organizar, analisar, interpretar e processar dados biológicos através de diferentes ferramentas e tecnologias (figura 1).
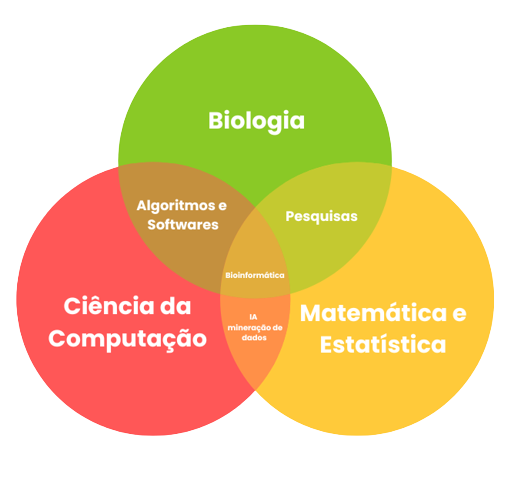
Griffiths et al (2008) define a Bioinformática como sistema de informação computacional e métodos analíticos aplicados a problemas biológicos. Já Thampi (2009), complementa que a Bioinformática é uma área que está no cruzamento da ciência experimental e teórica, e não é apenas sobre a modelagem de dados ou “mineração”, trata-se de compreender o mundo molecular que alimenta a vida a partir de perspectivas evolutivas.

Um breve histórico
Em 1953, um artigo publicado por James Watson e Francis Crick, publicado na revista Nature, mudou a história da ciência mundial. Watson e Crick descreveram a estrutura da molécula de DNA como uma dupla hélice espiralada, porém a descoberta atraiu pouca atenção da comunidade científica na época. Mas, somente em 1957 que o estudo ganhou notoriedade, quando os cientistas comprovaram que o DNA se auto replicava, algo que já haviam previsto em 1953.
Estes momentos desencadearam uma revolução nas investigações científicas ligadas às ciências da vida e foi a chave para o nascimento da bioinformática, devido às ferramentas que os cientistas usaram em suas descobertas.
Foi no começo dos anos de 1970 que o termo bioinformática foi originalmente usado pelos biólogos Paulien Hogeweg e Ben Hesper para definir “O estudo dos processos informáticos em sistemas bióticos”. Porém a físico-química norte-americana Margaret Dayhoff, foi quem ficou conhecida como a “mãe da bioinformática”, devido ser a pioneira na aplicação de métodos matemáticos e computacionais para determinar sequências de peptídeos.
Em 1965 Dra. Dayhoff participou da criação do “Atlas of Protein Sequence and Structure”, o primeiro banco de dados público computadorizado de sequências de proteínas.
Funções Típicas
Segundo Lorenzoni (2019) são:
- Desenvolvimento de novos algoritmos e estatísticas;
- Análise e interpretação de vários tipos de dados biológicos;
- Desenvolvimento e implementação de ferramentas que permitem acesso e gerenciamento eficientes de diferentes tipos de informações.
- Análise de sequência que inclui alinhamento de sequência, pesquisa em banco de dados, descoberta de motivos e padrões, descoberta de genes e promotores, reconstrução de relações evolutivas e montagem e comparação de genoma.
- Análises estruturais que incluem análise, comparação, classificação e previsão de proteínas e estruturas de ácidos nucleicos.
- Análise funcional que inclui perfil de expressão gênica, previsão de interação proteína-proteína, previsão de localização subcelular, reconstrução e simulação de vias metabólicas.
Ferramentas
Existem inúmeros projetos de genomas que, cujo os dados gerados, são disponibilizados online e gratuitamente. Podemos destacar três bancos de dados que são atualizados diariamente:
- O NCBI (National Center for Biotechnology Information), um dos melhores repositórios de sequências de DNA e RNA, localizado nos Estados Unidos.
- A KEGG (Kyoto Encyclopedia of Genes and Genomes) é uma enciclopédia japonesa com diferentes repositórios de informações biológicas além de ser uma ferramenta de mapas metabólicos.
- O UniProt (Universal Protein Resource), um banco de dados de proteínas suíço, que disponibiliza excelentes ferramentas de anotações de sequências de proteínas e estruturas tridimensionais.
Além dos bancos de dados mencionados existem muitas outras ferramentas utilizadas pelos bioinformatas, como as linguagens de programação. Python, R, Shell Script, Julia e Rust são comumente utilizados para a criação de ferramentas e scripts em bioinformática.
As linguagens Python e R são preferidas em análises biológicas por serem simples e de fácil entendimento e aprendizado, além de oferecerem vantagens nas análises de dados.
O Python é uma linguagem que possui várias ferramentas para a biologia molecular, suporta vários arquivos comumente utilizados em bioinformática além de ser integrado a um banco de dados para sequências moleculares. O BioSQL.
O R por sua vez, oferece ferramentas estatísticas, pois é uma ferramenta destinada à ciência de dados.
Tanto o Python como o R oferecem pacotes especializados para análise e gerenciamento de dados. Temos o Biopython, XGBoost, Sklearn, Pandas e o Flask para o Python. Enquanto que para o R temos Bioconductor.
Objetivos
Atualmente, a Bioinformática tem o objetivo de solucionar questionamentos e problemas biológicos usando a modelos computacionais, a fim de otimizar o trabalho de análise e interpretação de dados das moléculas biológicas, onde esse processo é denominado de biologia computacional.
Uma vez que ao entender como determinado DNA funciona é possível prevenir e combater doenças com medicamentos e tratamentos genéticos mais eficientes, combater mudanças climáticas desenvolvendo e aplicando métodos sustentáveis, favorecer o desenvolvimento da agricultura de maneira sustentável e segura com cultivos mais resistentes às pragas, às mudanças climáticas e livre de agrotóxicos, por exemplo, favorecendo assim melhor qualidade de vida a todos os seres vivos.
Bioinformática no Brasil
No final do ano 1999, os cientistas João Meidanis e João Carlos Setúbal, ambos ligados ao Centro de Computação da UNICAMP (Universidade de Campinas), que utilizaram softwares para realizar o sequenciamento completo do DNA de uma bactéria que causava prejuízos à cultura de cítricos, a Xylella fastidiosa, considerada uma praga para plantações de laranja por causar uma doença denominada de clorose variegada dos citros (CVC), popularmente chamada de amarelinho.
De acordo com o artigo, o genoma sequenciado consiste em um cromossomo circular de 2.679.305 pares de bases (pb) rico em nucleotídeos GC.
Segundo Tavares (2022) o projeto Xylella custou 13 milhões de dólares e foi adquirido no consórcio ONSA (Organization for Nucleotide Sequencing and Analysis – The Virtual Genomics Institute). Esse consórcio integrou centros de pesquisas em projetos diversos para sequenciamento de DNA em larga escala, fazendo a montagem do genoma da Xyllela abrir caminho para o sucesso na montagem de outros genomas, como é o caso de Xanthomonas citri, Xanthomonas campestris, Lifsonia xyli e uma cepa de Xyllela que ataca uvas, tornando o Brasil uma referência em montagem de genomas de organismos relacionados com a agricultura.
Ainda segundo Tavares (2022) o país também se destacou na pesquisa do câncer ao estudar genes relacionados a diversos tipos da doença e tumores malignos.

Referências Bibliográficas
- Welch, L. et al. Bioinformatics Curriculum Guidelines: Toward a Definition of Core Competencies. PLOS Computational Biology. 2014.
- Bioinformata: 6 dicas para trabalhar com bioinformática, Dezordi, Filipe, disponível em<https://blog.varsomics.com/bioinformata-profissao/#:~:text=6.-,Qual%20o%20salário%20de%20um%20bioinformata%3F,como%20baixo%20e%20alto%2C%20respectivamente>
- THAMPI, S. M. Introduction to Bioinformatics.arXiv preprint arXiv. ComputationalEngineering, Financeand Science, 2009.
- GRIFFITHS, A. J. F.; WESSLER, S. R.; LEWONTIN, R. C.; CARROLL, S. B. Introdução a Genética. 9ed. Guanabara Koogan, 2008.
- Mulder NJ, Adebiyi E, Adebiyi M, et al. Development of Bioinformatics Infrastructure for Genomics Research. Glob Heart. 2017;12(2):91-98. doi:10.1016/j.gheart.2017.01.005
- Oliver GR, Hart SN, Klee EW. Bioinformatics for clinical next generation sequencing. Clin Chem. 2015;61(1):124-135. doi:10.1373/clinchem.2014.224360
- Bioinformática: união entre ciência e tecnologia.Safady, Nágela G. disponível em<https://blog.varsomics.com/bioinformatica/#:~:text=tridimensionais%20das%20proteínas.-,Quando%20surgiu%20a%20bioinformática%3F,como%20a%20mãe%20da%20bioinformática.>
- Bioinformática e Biologia Computacional, Biotecnologia, Ciência, Produção Científica, Profissional, V.2 (2017), Douglas Souza Vieira
- Bioinformática no Brasil: uma história recente, 2022. Tavares, Thayana, disponível em <https://blog.neoprospecta.com/bioinformatica-no-brasil/ >
- Bioinformática - Parte II: Fundamentos e Aplicações, 2019, Lorenzoni, Rodrigo Monte, disponível <https://www.laborgene.com.br/fundamentos-da-bioinformatica/>
A Revelo Content Network acolhe todas as raças, etnias, nacionalidades, credos, gêneros, orientações, pontos de vista e ideologias, desde que promovam diversidade, equidade, inclusão e crescimento na carreira dos profissionais de tecnologia.